
一、什么是用户画像
用户画像又称用户角色,作为一种勾画目标用户、联系用户诉求与设计方向的有效工具,用户画像在各领域得到了广泛的应用。我们在实际操作的过程中往往会以最为浅显和贴近生活的话语将用户的属性、行为与期待的数据转化联结起来。作为实际用户的虚拟代表,用户画像所形成的用户角色并不是脱离产品和市场之外所构建出来的,形成的用户角色需要有代表性,能代表产品的主要受众和目标群体。
二、用户画像规划的基本流程
1. 数据采集
对用户数据进行采集,数据预处理,数据挖掘和过滤等手段得出期望的数据集。
用户数据一般分为埋点数据和业务数据:
埋点数据:根据用户的行为特征进行埋点,将得到的数据进行处理存储;业务数据:用户的姓名、年龄、地理位置等自然属性,同时包括用户购买、用户评价、用户评论等隐形数据。具体采集方法可以使用如下算法模型:
文本挖掘模型(TF-IDF):处理文本类型,提取数据信息。
TF是词频,IDF是逆向文件频率,TF-IDF是词频和逆向文件频率的乘积。
Nij就是词i在j文章中出现的次数,分母就是文章的总词数。
D就是语料库中文件总数,下面分母就是词i出现的文档数,然后取对数。
该算法可以直接调用python库Sklearn进行实现,但是该算法比较单一,不考虑词条在文章中的位置,不能准确描述词的重要程度,一般需要结合其他其他算法或者增加权重改进。
聚类算法:聚类算法较多,如ANN神经网络和贝叶斯等,聚类主要是针对冷启动用户、用户分群营销等目的;具体算法相对复杂,目前算法应用多使用python的各种库如Sklearn,包括一些框架tensorflow、caffe等。
相似度模型:一般使用相似度模型进行辅助用户分群,常用的有逻辑回归、线性回归、余弦相似度、皮尔森相似度等。
具体说下余弦相似度: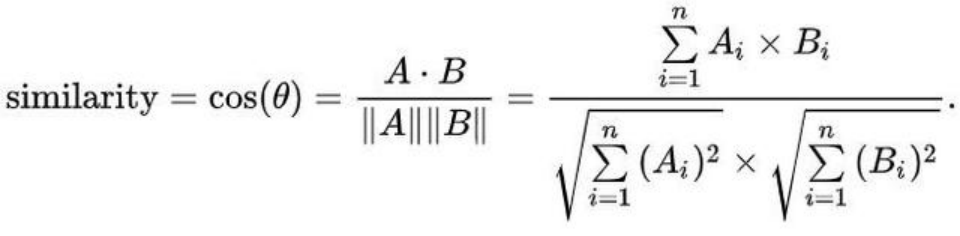
实例:
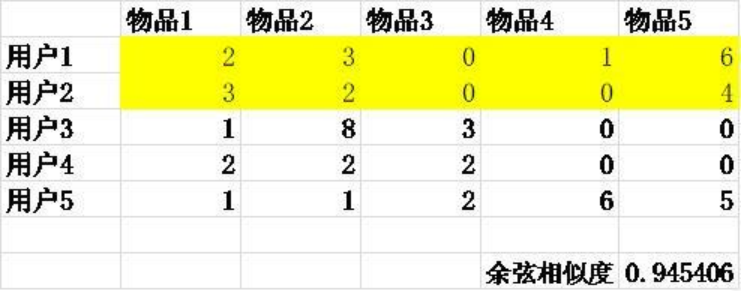
用户1和用户2通过公式计算相似度为0.945406,是不是可以解释为两个用户可以划分为同一类人,进行用户分群(计算过程只是用于解释算法,无其他意义)。
若已有数据仓库,数据采集相对比较轻松,可参考文章“每日优鲜如何搭建数据仓库?”。
2. 用户维度分析
用户分析具有多维度,随时间更新的特点,包括用户年纪、学历、兴趣、消费水平等都容易变化。
因此维度信息应该随着用户偏好发生变化,因此,在标签系统中需要有新增标签功能。
3. 维度标签化
用户画像最终的实现应该是对维度进行标签化,常用MECE法则进行标签化,防止标签界限不清晰。
标签需要根据需要进行逐级拆分,例如:
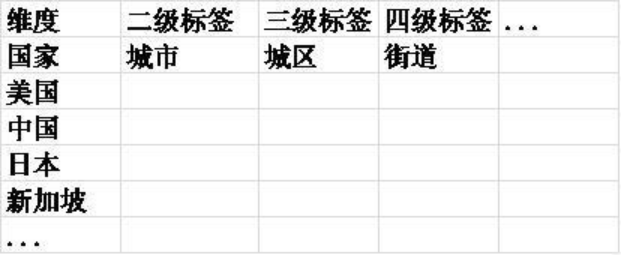
4. 标签映射,接口封装
用户画像数据导入服务器中,为后续推荐系统,营销活动服务;封装成API可以作为数据服务的内容,对其他系统提供数据支持。
5. 用户画像评估
用户覆盖率:用户画像具体能够覆盖到多少用户,有些用户画像可能覆盖总用户的50%或者80%;所以覆盖率是用户画像应用的一个评价,覆盖率越高,对后续精准营销的策略选择越准确。
准确率:模型的准确性,如上所述,使用算法模型导致的用户分群错误或者对用户的购买意向预测错误,将直接影响购买率,影响GMV。
可拓展:用户画像在维度刻画应该是可扩展的。
及时性:如果用户画像服务到实时推荐系统中还需要用户画像的及时。


让数据流动起来,开启业绩增长!
了解500+品牌零售商使用LinkFlow的场景用例



